AWS Install Guide
Getting Started
Welcome to the Diamanti Ultima Enterprise Installation Guide for AWS. This guide is intended for AWS virtual-machine environments. In addition, refer to the feature matrix in Appendix B for more information about supported and unsupported Diamanti features on this platform.
The purpose of this guide is to help you get started with the installation and configuration of the software in the AWS environment. The chapter begins by describing the supported VMs on AWS. The chapter then walks you through creating the cluster using UI based simple install and verifying the cluster health.
Note
This guide uses the word node to describe the VM on which the Diamanti distribution is installed.
Prerequisites
Before you start, make sure you have required details as mentioned below:
CFT template aws-ue-cft.yaml file provided by Diamanti for installation.
CFT template aws-ue-add-node-cft.yaml provided by Diamanti for adding nodes to the existing cluster.
AWS console login.
Supported Machine Types to create Nodes on AWS
Diamanti Ultima Enterprise 3.6.2 has the support for following machine types and label:
Machine types:
Machine Types |
vCPU |
Memory |
|---|---|---|
m5d.16xlarge |
64 |
256GiB |
i4i.16xlarge |
64 |
512GiB |
Supported Regions
This section lists the supported regions in AWS for Diamanti 3.6.2 release.
us-east-1 |
ca-central-1 |
eu-west-3 |
ap-southeast-2 |
us-east-2 |
eu-central-1 |
eu-north-1 |
ap-northeast-1 |
us-west-1 |
eu-west-1 |
ap-south-1 |
ap-northeast-2 |
us-west-2 |
eu-west-2 |
ap-southeast-1 |
ap-northeast-3 |
Installation
Start the Installation
On AWS console, search for the key pairs and select the Key pairs.

Select the Create key pair.
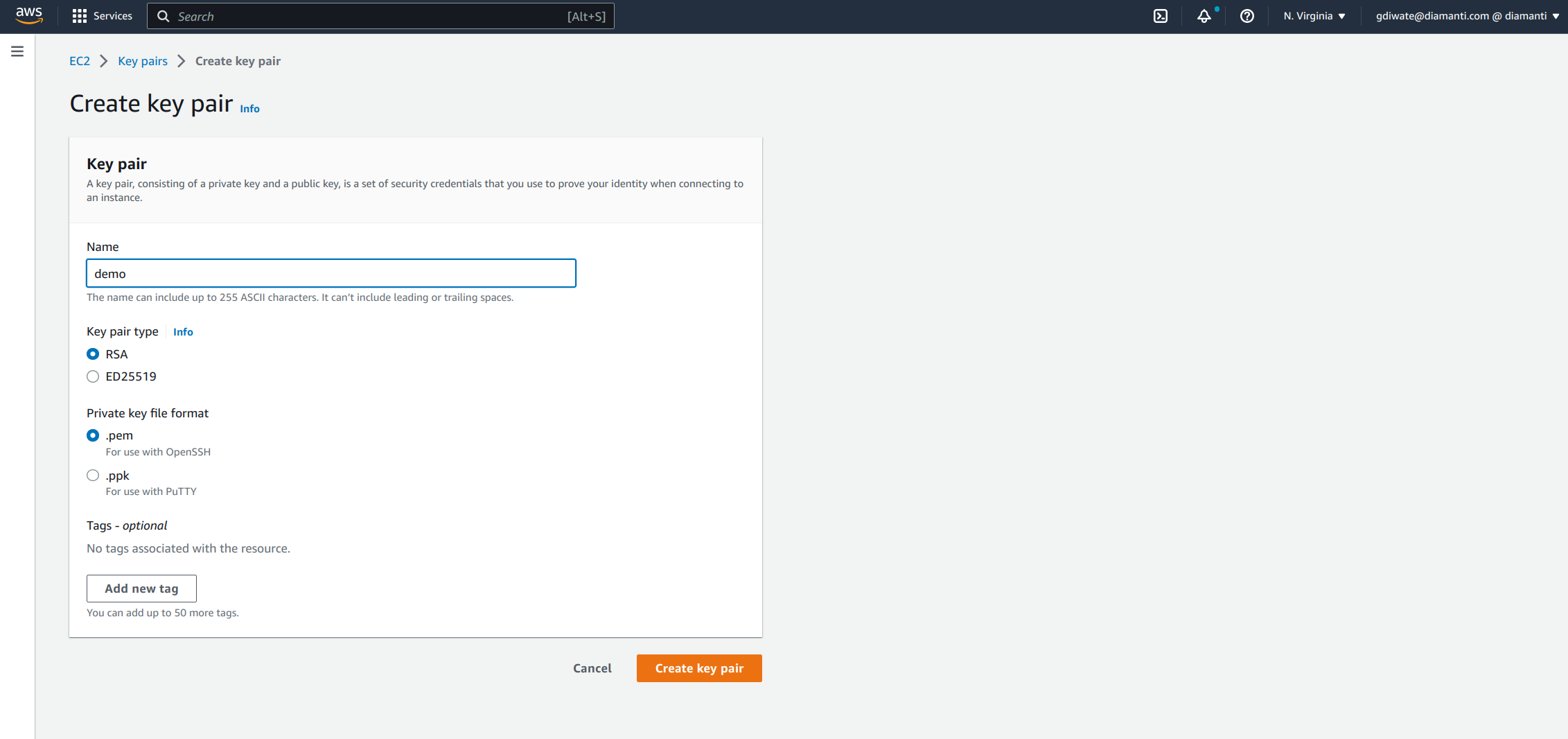
Enter the details and select Create a key pair.
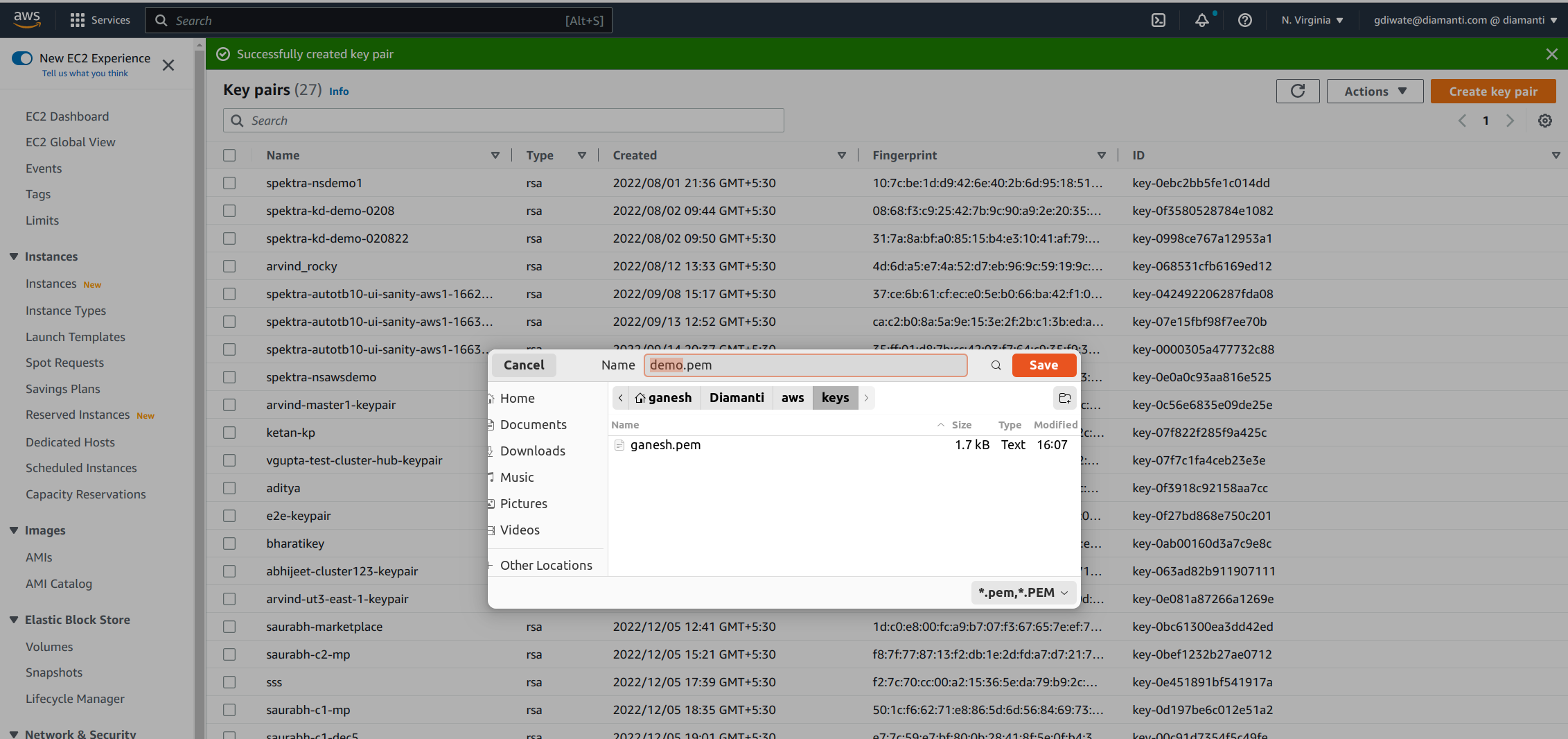
Save the key pair on your computer.
Select Services and then select CloudFormation.
Select Create stack and then select With new resources (standard).
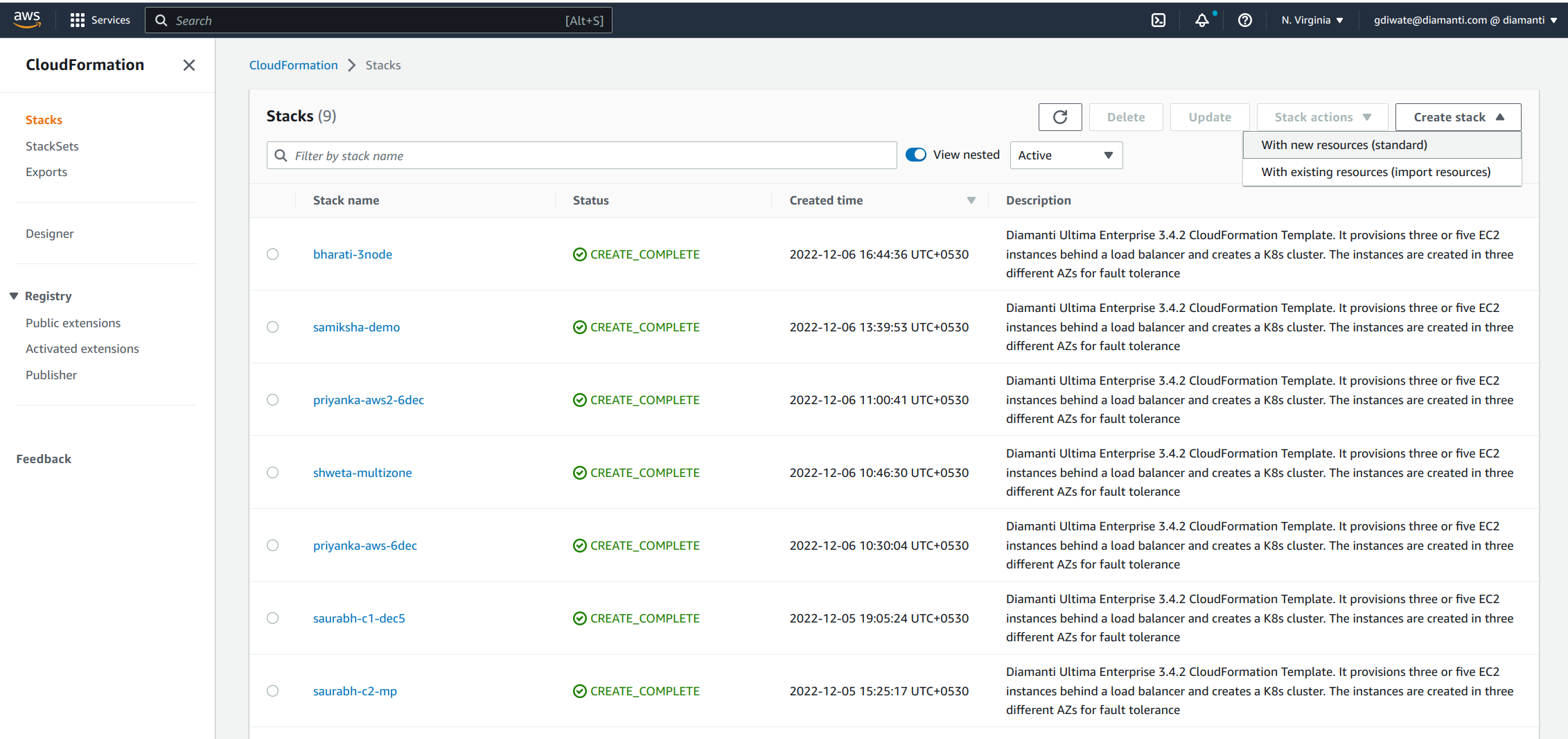
Select Prepare template. In the Specify Template section select the template source as Upload a template file to upload a yaml file, and select Next.
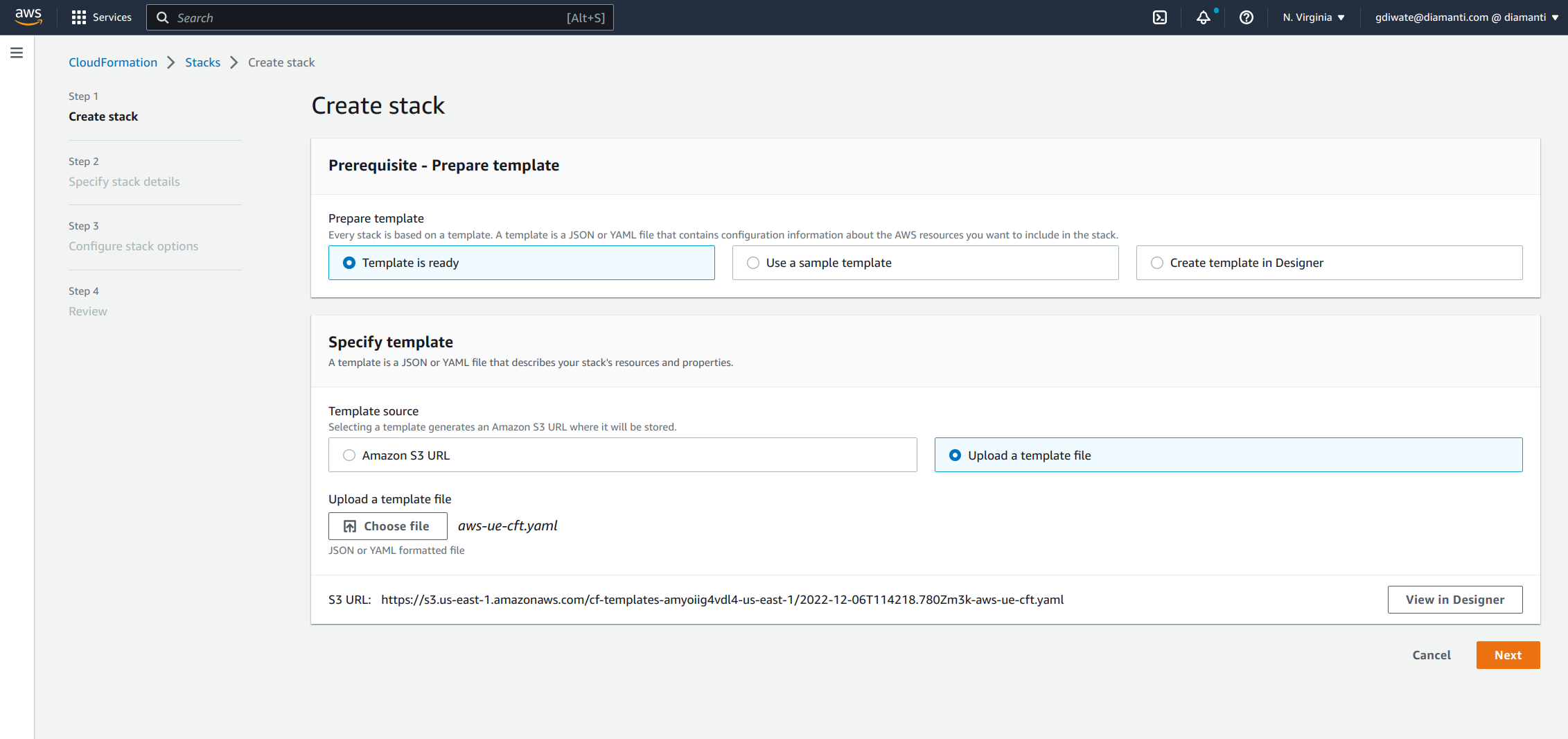
Specify the stack details and select Next.
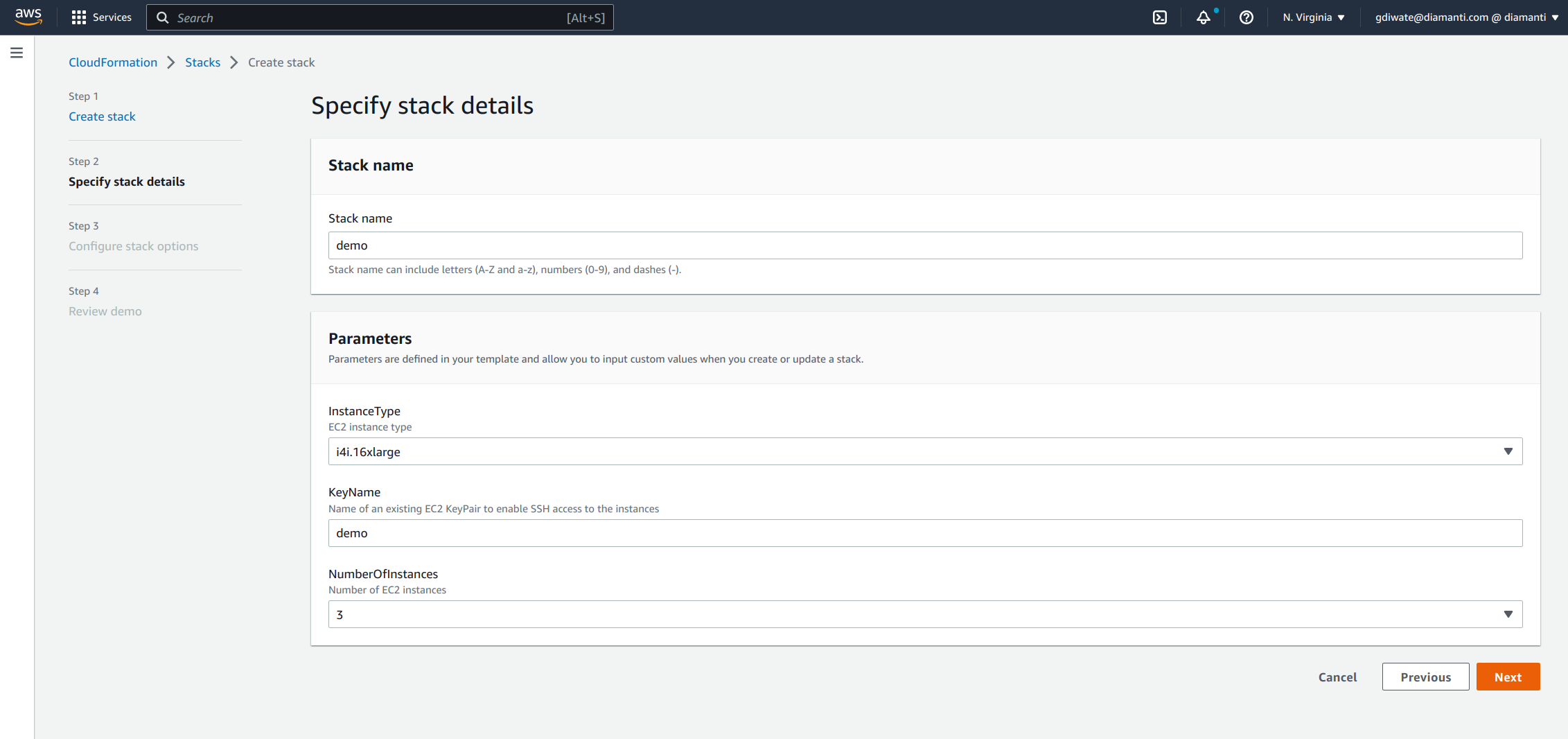
Configure the stack options and select Next.
Review the stack details and select Submit.
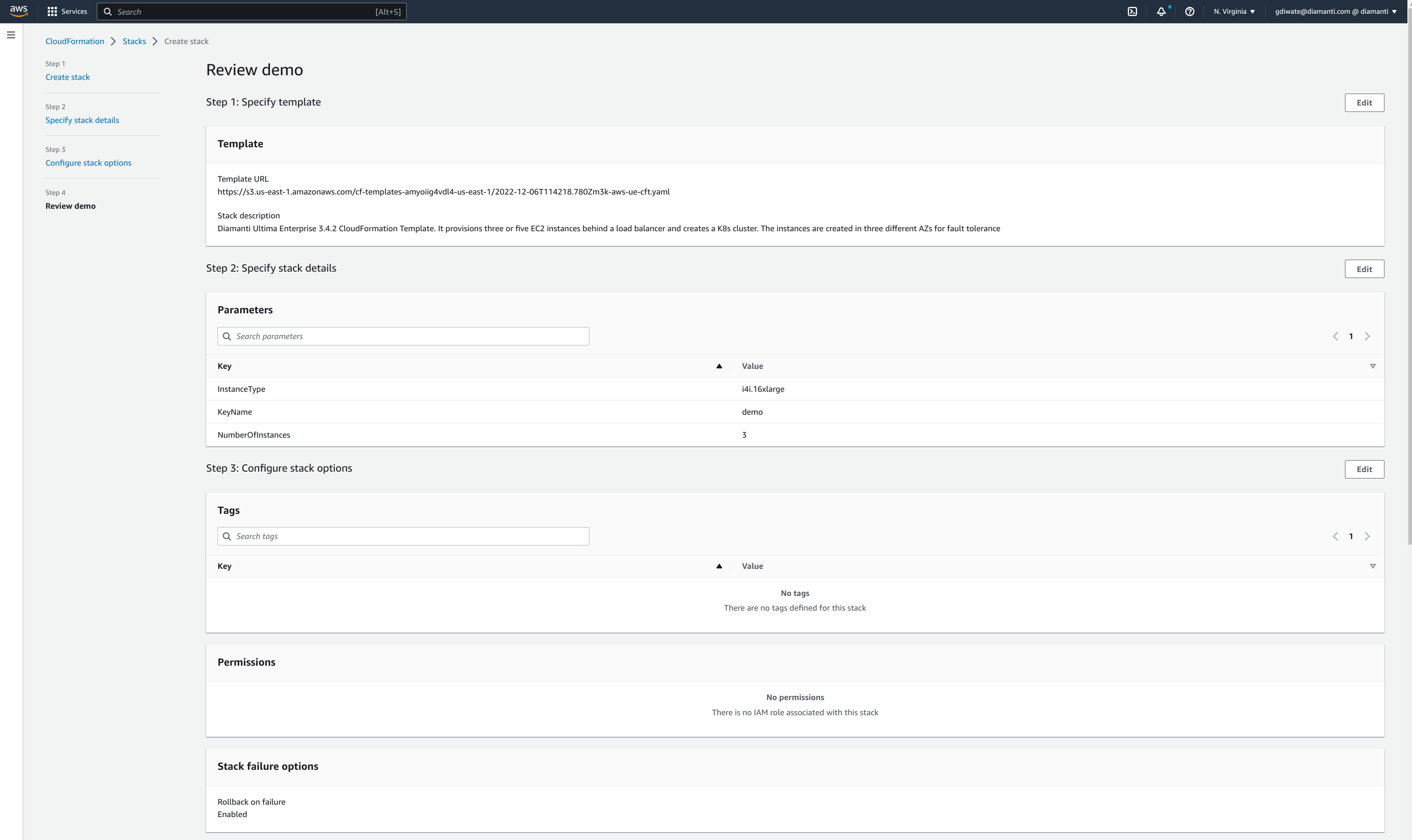
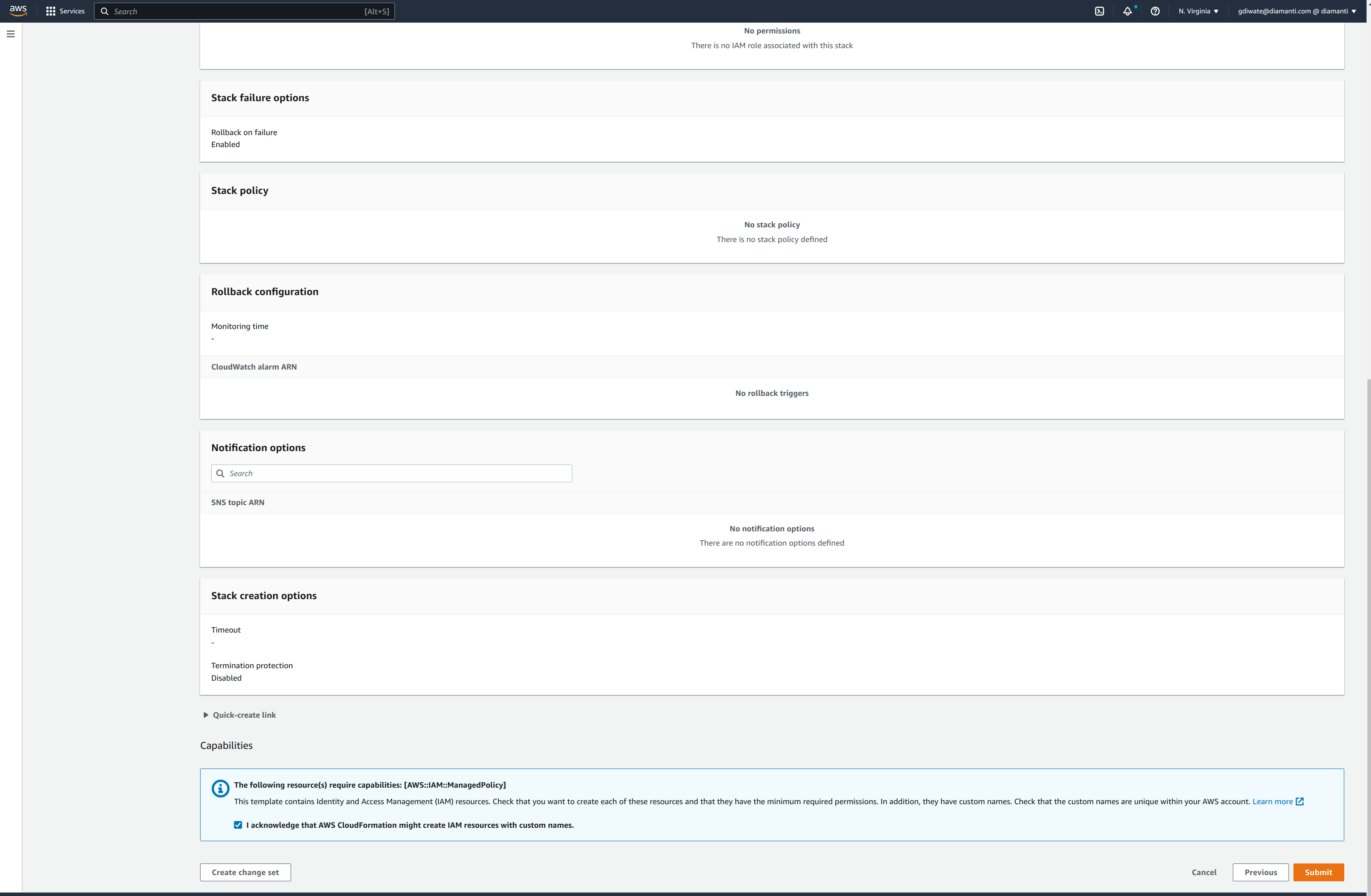
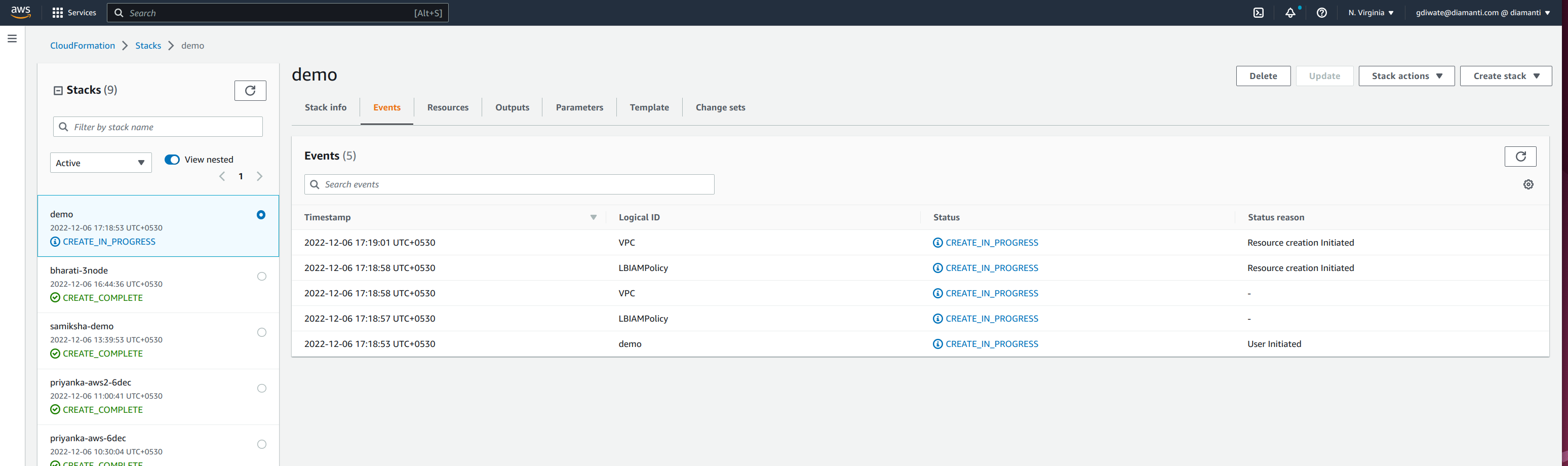
- The stack is in create_in_progress state while the cluster is created.
resources.
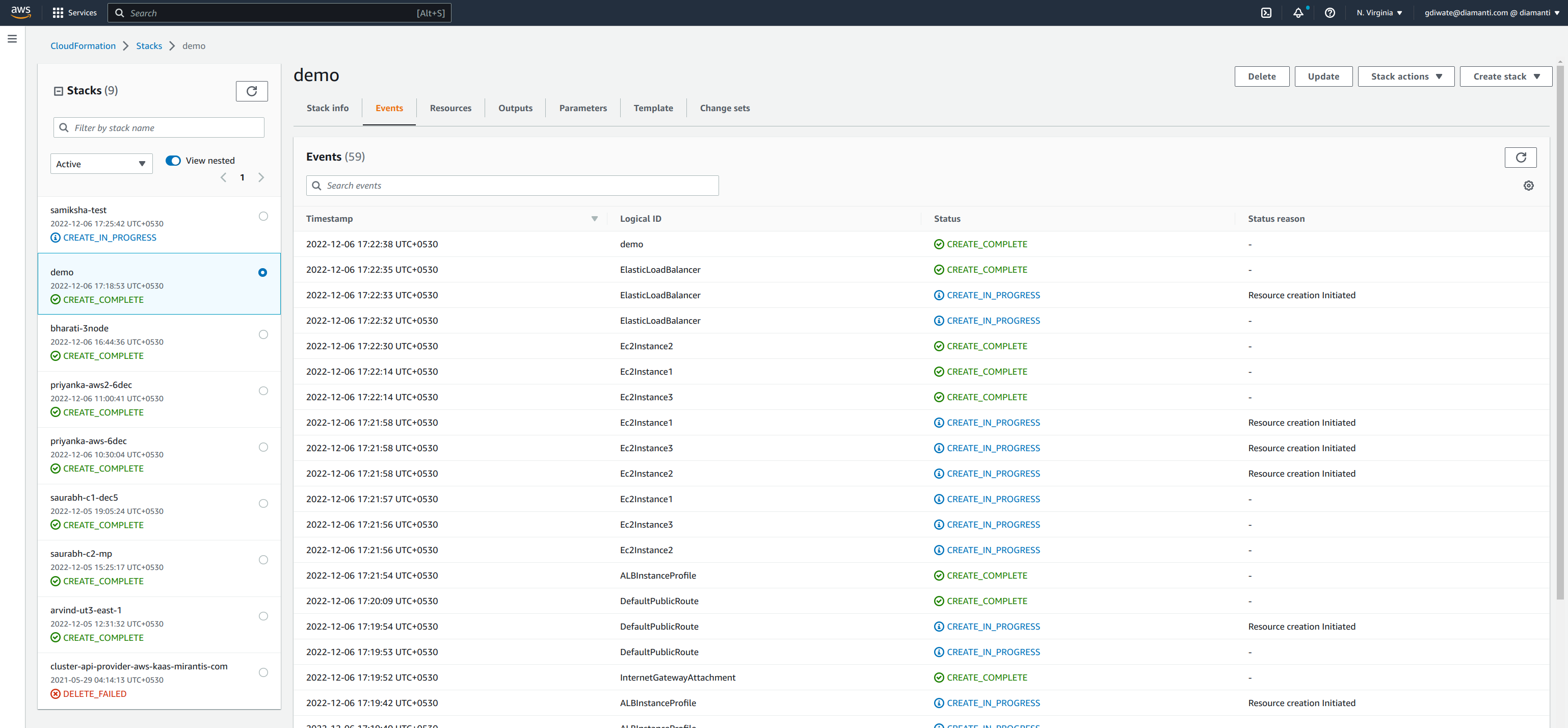
Once all the resources are created, stack status displays as CREATE_COMPLETE.
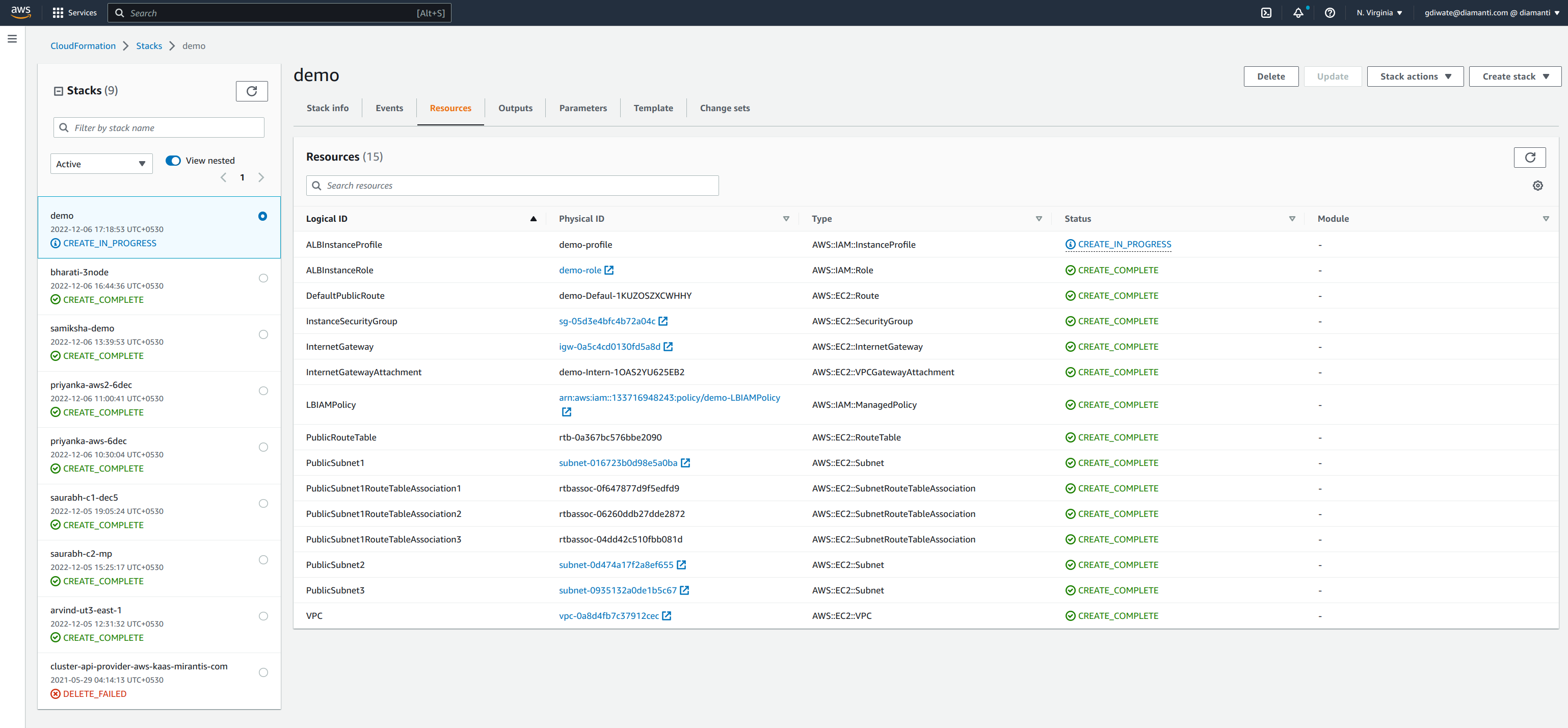
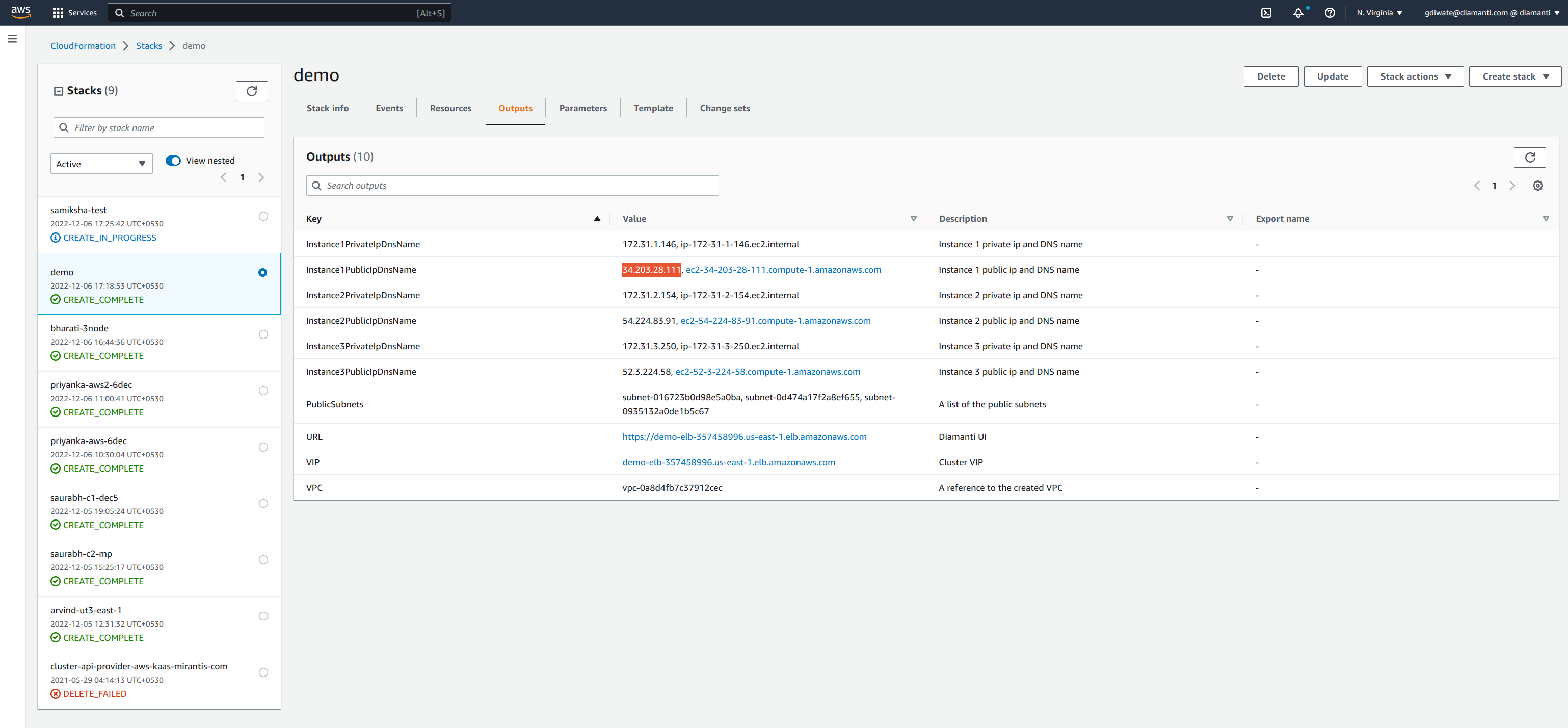
In the Outputs tab, you will see cluster details once the cluster resources are ready.
Login to one of the instances using the key pair.
qaserv2:~/AWS> chmod 400 demo.pem qaserv2:~/AWS> ls -l demo.pem -r-------- 1 demo eng 1674 Jan 2 2023 demo.pem qaserv2:~/AWS> ssh -i demo.pem diamanti@23.22.205.155 The authenticity of host '23.22.205.155 (23.22.205.155)' can't be established. ECDSA key fingerprint is SHA256:1cVW9qKNvjcq0G+6zXPBbfdyg9OxBwmockQeANalHOs. ECDSA key fingerprint is MD5:9d:8f:ff:6e:38:e2:03:6c:be:6a:47:15:02:96:12:3a. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added '23.22.205.155' (ECDSA) to the list of known hosts. Rocky Linux 8.6 (Green Obsidian) Kernel 4.18.0-372.9.1.el8.x86_64 on an x86_64 Last login: Mon Jul 24 17:53:20 2023 from 38.83.0.140
Run diamani-cluster-create.sh by specifying your stack name.
[diamanti@ip-172-31-1-253 ~]$ diamanti-cluster-create.sh demo Validating input (will take less than 1 minute) Getting instance inventory (will take less than 1 minute) Waiting for instances to be ready (will take up to 15 minutes) Creating ue cluster (will take about 3 minutes) [diamanti@ip-172-31-1-253 ~]$ ls create-cluster.log demo-inventory.data [diamanti@ip-172-31-1-253 ~]$ cat demo-inventory.data Cluster vip : 204.236.208.253 Cluster vip dns name : demo-elb-1439424503.us-east-1.elb.amazonaws.com Node 1 instance id : i-05ac4f57eb2c60257 Node 1 external ip : 54.198.158.239 Node 1 hostname : ip-172-31-1-72.ec2.internal (master) Node 2 instance id : i-0ed99e78186d49cbb Node 2 external ip : 44.201.153.42 Node 2 hostname : ip-172-31-3-253.ec2.internal (master) Node 3 instance id : i-0e6a3298a866a5e85 Node 3 external ip : 3.231.227.55 Node 3 hostname : ip-172-31-2-91.ec2.internal (master)You can check the installation logs in the create-cluster.log file.
Run the following command after you log in to VIP and see the cluster status after the cluster is created.
dctl –s 204.236.208.253 login –u admin –p Diamanti@111 [diamanti@ip-172-31-1-72 ~]$ dctl -s 204.236.208.253 login -u admin -p Diamanti@111 Name : demo Virtual IP : 204.236.208.253 Server : demo.ec2.internal WARNING: Thumbprint : 4c 72 25 f3 db b9 e8 6a ce ab 90 45 a0 82 8e e7 c8 53 df 24 8e a1 83 9f 55 6e a0 77 13 26 1d 2e [CN:diamanti-signer@1695194375, OU:[], O=[] issued by CN:diamanti-signer@1695194375, OU:[], O=[]] Configuration written successfully Successfully logged in qaserv2:~> dctl cluster status Name : demo UUID : 0d77636a-5786-11ee-bf0a-0eeb9dc3bba1 State : Created Version : 3.6.2 (62) Etcd State : Healthy Virtual IP : 204.236.208.253 Pod DNS Domain : cluster.local NAME NODE-STATUS K8S-STATUS ROLE MILLICORES MEMORY STORAGE SCTRLS LOCAL, REMOTE ip-172-31-1-72.ec2.internal Good Good master* 7100/64000 25.07GiB/256GiB 0/2.28TB 0/64, 0/64 ip-172-31-2-91.ec2.internal Good Good master 7100/64000 25.07GiB/256GiB 0/2.28TB 0/64, 0/64 ip-172-31-3-253.ec2.internal Good Good master 7200/64000 25.26GiB/256GiB 0/2.28TB 0/64, 0/64- Login from the periscope using the Virtual IP shown in the cluster status.
To login use:
https://<VIP> The following image displayes the Dashboard after login:
The following image displayes the Dashboard after login: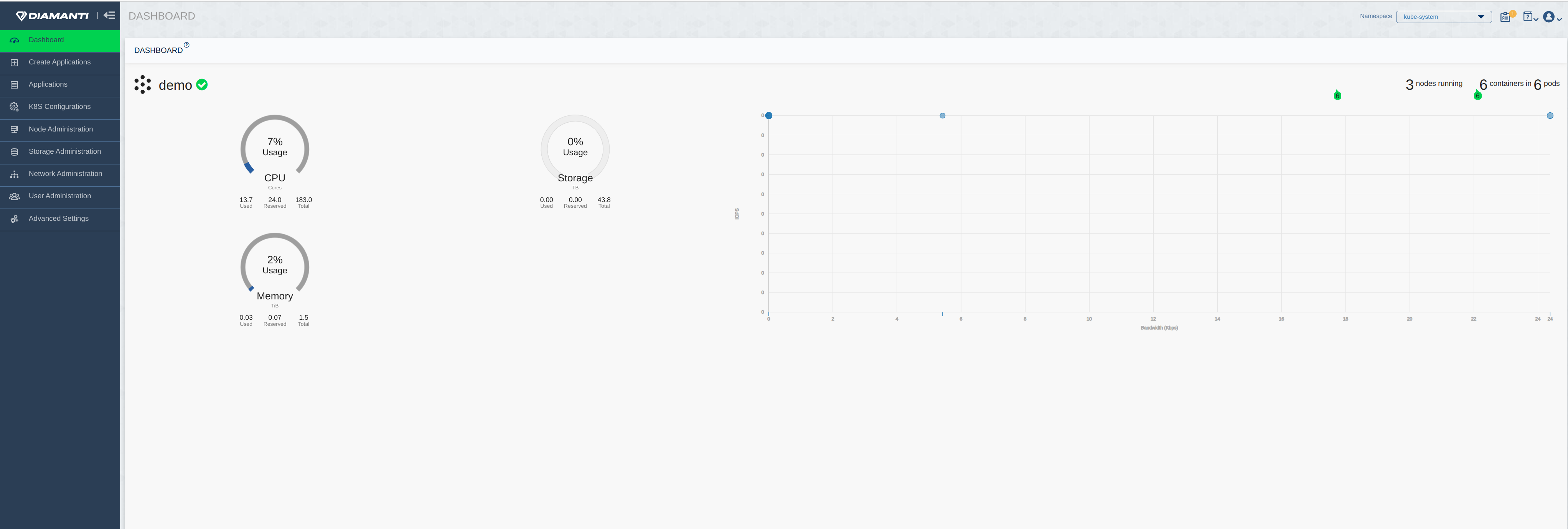 The following image displays the summary of Applications in diamanti-system namespace.
The following image displays the summary of Applications in diamanti-system namespace.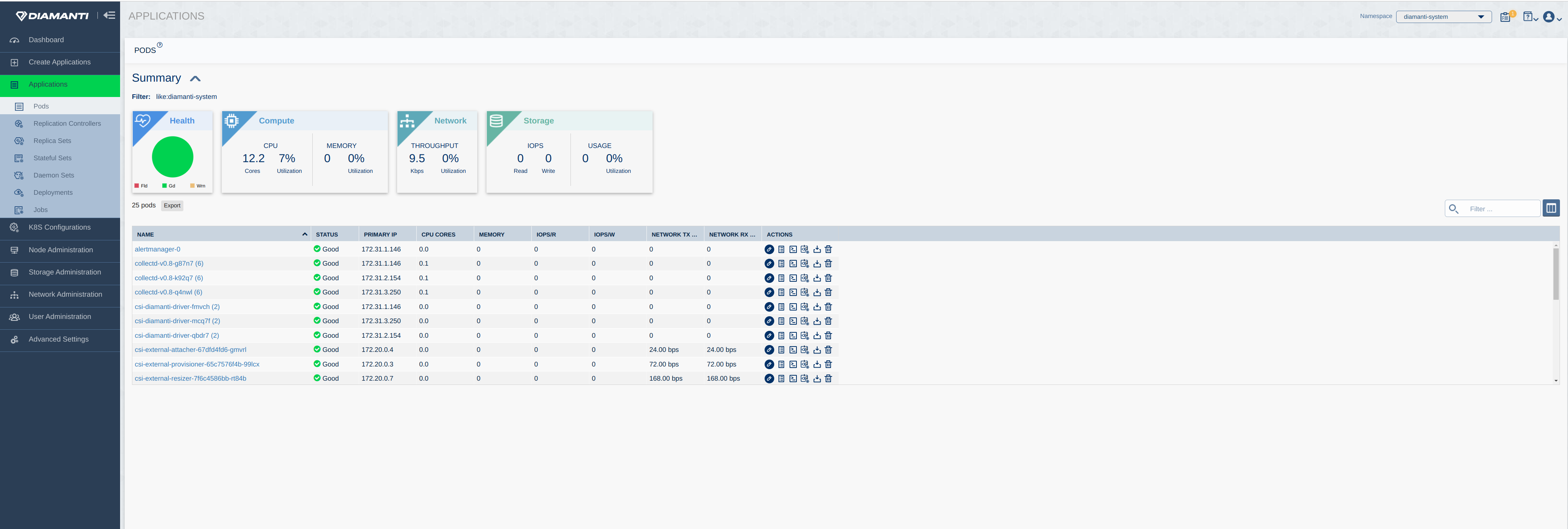 The following image displays the summary of Applications in kube-system namespace.
The following image displays the summary of Applications in kube-system namespace.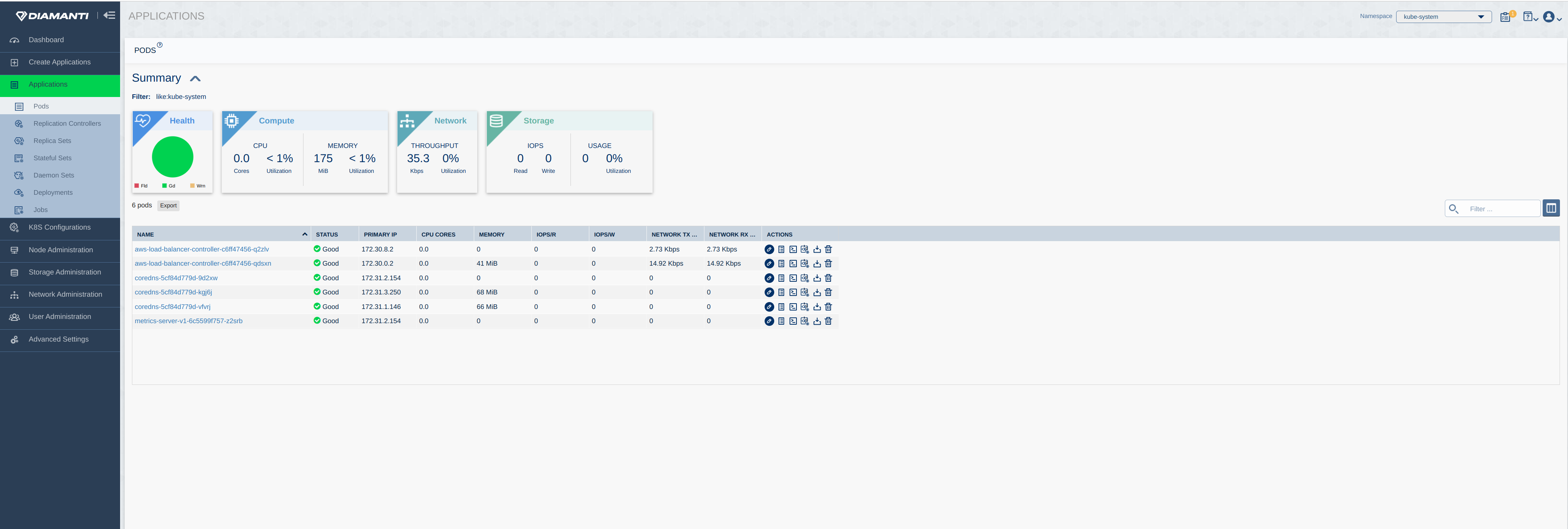 The following image displays the summary of Nodes:
The following image displays the summary of Nodes: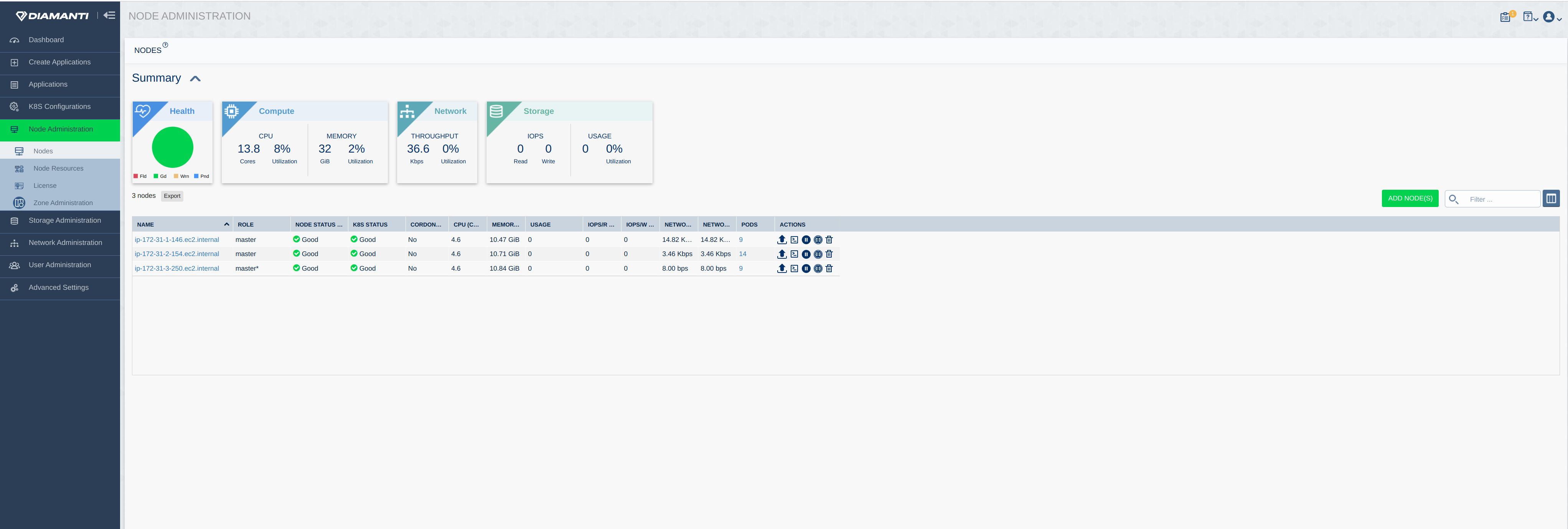 The following image displays the Licenses status and list:
The following image displays the Licenses status and list: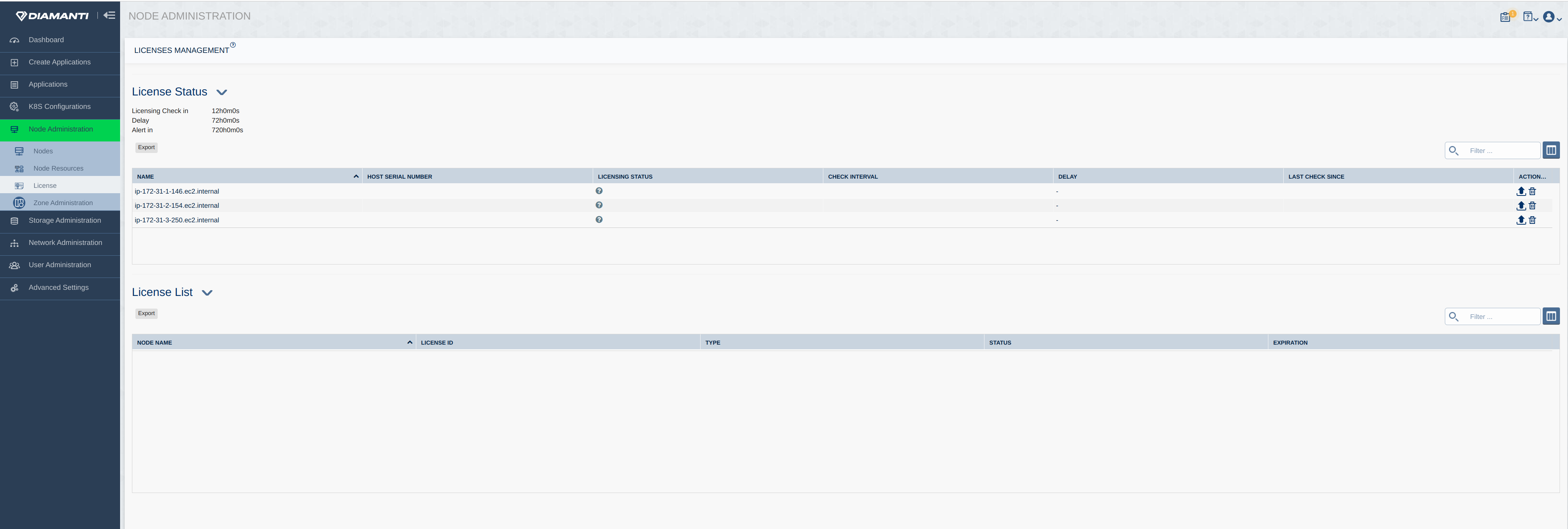 The following image displays the Drives:
The following image displays the Drives: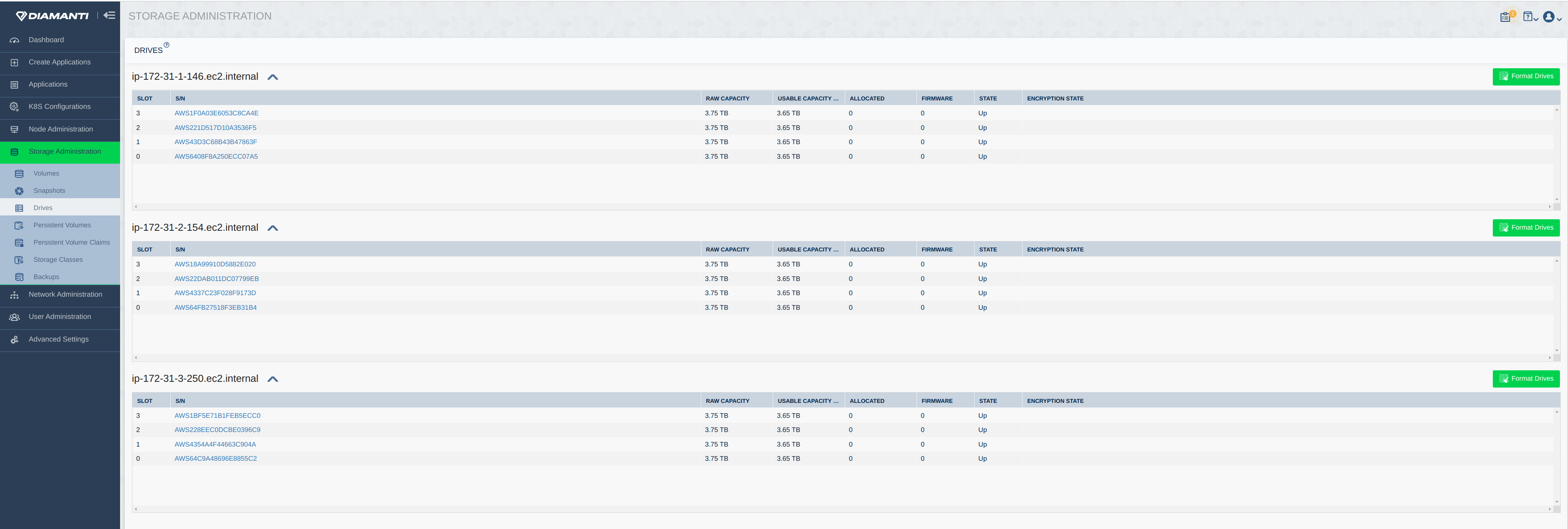
Run the following command to view the applications on cluster in diamanti-system and kube-system namespace.
$ qaserv2:~> kubectl get po -n diamanti-system NAME READY STATUS RESTARTS AGE alertmanager-0 1/1 Running 0 21m collectd-v0.8-lpm4d 6/6 Running 0 21m collectd-v0.8-p7f4z 6/6 Running 6 21m collectd-v0.8-rjf4c 6/6 Running 0 21m csi-diamanti-driver-5zvqt 2/2 Running 0 21m csi-diamanti-driver-ccfz7 2/2 Running 2 21m csi-diamanti-driver-glvzm 2/2 Running 0 21m csi-external-attacher-5b585cf688-8l2pc 1/1 Running 0 21m csi-external-provisioner-67748d4b56-vt4s5 1/1 Running 0 21m csi-external-resizer-667966cdf8-ff7lp 1/1 Running 0 21m csi-external-snapshotter-5cbcdcbdcf-ftzr9 1/1 Running 0 21m dcx-ovs-daemon-85d7z 1/1 Running 0 21m dcx-ovs-daemon-9rgr6 1/1 Running 1 21m dcx-ovs-daemon-ntstm 1/1 Running 1 21m default-target-re-deployment-2023-07-28t10-09-29z-66b478cbmxfgn 1/1 Running 0 21m diamanti-dataservice-operator-569b7c96b6-hc2xt 1/1 Running 0 21m diamanti-dssapp-medium-lz7s7 1/1 Running 0 21m diamanti-dssapp-medium-qb4st 1/1 Running 1 21m diamanti-dssapp-medium-qhrhx 1/1 Running 0 21m nfs-csi-diamanti-driver-8bxtd 2/2 Running 2 21m nfs-csi-diamanti-driver-gjdkz 2/2 Running 0 21m nfs-csi-diamanti-driver-wm8ck 2/2 Running 0 21m prometheus-v1-0 1/1 Running 0 21m prometheus-v1-1 1/1 Running 0 21m prometheus-v1-2 1/1 Running 0 21m snapshot-controller-59f5bf9945-kg8r7 1/1 Running 0 21m
$ qaserv2:~> kubectl get po -n kube-system NAME READY STATUS RESTARTS AGE aws-load-balancer-controller-dc4666b48-6qfbq 1/1 Running 0 21m aws-load-balancer-controller-dc4666b48-wtc7z 1/1 Running 0 21m coredns-78f98b789f-jcc59 1/1 Running 0 21m coredns-78f98b789f-lvz4h 1/1 Running 0 21m coredns-78f98b789f-vjlhw 1/1 Running 0 21m metrics-server-6b45b6d676-zsfz6 1/1 Running 0 21m
- Run the following command for drive list:
$ qaserv2:~> dctl drive list NODE SLOT S/N DRIVESET RAW CAPACITY USABLE CAPACITY ALLOCATED FIRMWARE STATE SELF-ENCRYPTED ip-172-31-1-253.ec2.internal 0 AWS1CBAB362EA87AC87E d912cb01-fda8-4edc-bf24-cbc7e5ce8eca 600GB 570.69GB 501.35MB 0 Up No ip-172-31-1-253.ec2.internal 1 AWS23909B51C052DA8E1 d912cb01-fda8-4edc-bf24-cbc7e5ce8eca 600GB 570.69GB 501.35MB 0 Up No ip-172-31-1-253.ec2.internal 2 AWS22917D46CF76B270E d912cb01-fda8-4edc-bf24-cbc7e5ce8eca 600GB 570.69GB 501.35MB 0 Up No ip-172-31-1-253.ec2.internal 3 AWS15183256971394FA5 d912cb01-fda8-4edc-bf24-cbc7e5ce8eca 600GB 570.69GB 501.35MB 0 Up No ip-172-31-2-82.ec2.internal 0 AWS1D169914CE084DA12 0edbff32-5e8a-4187-876b-0455aa5d306b 600GB 570.69GB 501.35MB 0 Up No ip-172-31-2-82.ec2.internal 1 AWS22951734757C1ECB5 0edbff32-5e8a-4187-876b-0455aa5d306b 600GB 570.69GB 501.35MB 0 Up No ip-172-31-2-82.ec2.internal 2 AWS130C7C3B8A18754AD 0edbff32-5e8a-4187-876b-0455aa5d306b 600GB 570.69GB 501.35MB 0 Up No ip-172-31-2-82.ec2.internal 3 AWS22A1BE9C2876D4347 0edbff32-5e8a-4187-876b-0455aa5d306b 600GB 570.69GB 501.35MB 0 Up No ip-172-31-3-195.ec2.internal 0 AWS2F87E3456D078C6B4 f4ee3892-60d5-4089-89fd-14be723a6c79 600GB 570.69GB 501.35MB 0 Up No ip-172-31-3-195.ec2.internal 1 AWS237D72DB06E8F1996 f4ee3892-60d5-4089-89fd-14be723a6c79 600GB 570.69GB 501.35MB 0 Up No ip-172-31-3-195.ec2.internal 2 AWS2A4AF00FC773608E4 f4ee3892-60d5-4089-89fd-14be723a6c79 600GB 570.69GB 501.35MB 0 Up No ip-172-31-3-195.ec2.internal 3 AWS251DCED33EF7F17C3 f4ee3892-60d5-4089-89fd-14be723a6c79 600GB 570.69GB 501.35MB 0 Up No
A successful installation and healthy cluster would be indicated by the outputs of the above verification.
Cluster deletion for AWS
Before you delete a cluster you must ensure the following
- Verify that all the applications are deleted.
Run the
dctl cluster statuscommand to check the status. If the storage soze is zero, it indicates that all the applications are deleted.$ dctl cluster status Name : demo UUID : 03f6caf3-5865-11ee-a945-12cea08adde5 State : Created Version : 3.6.2 (62) Etcd State : Healthy Virtual IP : 54.158.211.135 Pod DNS Domain : cluster.local NAME NODE-STATUS K8S-STATUS ROLE MILLICORES MEMORY STORAGE SCTRLS LOCAL, REMOTE ip-172-31-1-212.ec2.internal Good Good master 7200/64000 25.26GiB/256GiB 0/2.28TB 0/64, 0/64 ip-172-31-2-194.ec2.internal Good Good master 7100/64000 25.07GiB/256GiB 0/2.28TB 0/64, 0/64 ip-172-31-3-126.ec2.internal Good Good master* 7100/64000 25.07GiB/256GiB 0/2.28TB 0/64, 0/64
- Verify only the following services are running, else you must delete the other services.
Run the following command to check if only the required services are running.
$ kubectl get svc -A NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE default kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 72m diamanti-system alertmanager-svc ClusterIP 10.0.0.229 <none> 9093/TCP 72m diamanti-system collectd-svc ClusterIP 10.0.0.250 <none> 9103/TCP,9111/TCP,25826/UDP 72m diamanti-system csi-external-attacher ClusterIP 10.0.0.217 <none> 12445/TCP 72m diamanti-system csi-external-provisioner ClusterIP 10.0.0.121 <none> 12345/TCP 72m diamanti-system csi-external-resizer ClusterIP 10.0.0.172 <none> 12345/TCP 72m diamanti-system csi-external-snapshotter ClusterIP 10.0.0.146 <none> 12345/TCP 72m diamanti-system dataservice-operator-metrics ClusterIP 10.0.0.162 <none> 8383/TCP,8686/TCP 71m diamanti-system prometheus-svc ClusterIP 10.0.0.106 <none> 9090/TCP 72m diamanti-system virtvnc-resv NodePort 10.0.0.44 <none> 80:32000/TCP 72m kube-system aws-load-balancer-webhook-service ClusterIP 10.0.0.179 <none> 443/TCP 71m kube-system coredns ClusterIP 10.0.0.10 <none> 53/UDP,53/TCP,9153/TCP 72m kube-system metrics-server ClusterIP 10.0.0.185 <none> 443/TCP 72m
- Verify if only the system pods are running, else you must delete the other pods.
Run the following command to check if only the system pods are running.
$ kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE diamanti-system alertmanager-0 1/1 Running 0 73m diamanti-system collectd-v0.8-5cm4p 6/6 Running 0 73m diamanti-system collectd-v0.8-dxjk2 6/6 Running 0 73m diamanti-system collectd-v0.8-vc25p 6/6 Running 0 73m diamanti-system csi-diamanti-driver-2z47r 2/2 Running 0 73m diamanti-system csi-diamanti-driver-5df5b 2/2 Running 0 73m diamanti-system csi-diamanti-driver-hszm5 2/2 Running 0 73m diamanti-system csi-external-attacher-5b585cf688-xzrjs 1/1 Running 0 73m diamanti-system csi-external-provisioner-67748d4b56-f247j 1/1 Running 0 73m diamanti-system csi-external-resizer-667966cdf8-fs2kw 1/1 Running 0 73m diamanti-system csi-external-snapshotter-5cbcdcbdcf-xdt2v 1/1 Running 0 73m diamanti-system dcx-ovs-daemon-9x6vq 1/1 Running 1 (71m ago) 72m diamanti-system dcx-ovs-daemon-jtqpk 1/1 Running 0 72m diamanti-system dcx-ovs-daemon-lmtj8 1/1 Running 1 (72m ago) 72m diamanti-system diamanti-dataservice-operator-569b7c96b6-twcf5 1/1 Running 0 72m diamanti-system diamanti-dssapp-medium-fhmn7 1/1 Running 0 72m diamanti-system diamanti-dssapp-medium-g8ppv 1/1 Running 0 72m diamanti-system diamanti-dssapp-medium-smvgk 1/1 Running 0 72m diamanti-system nfs-csi-diamanti-driver-68fdc 2/2 Running 0 72m diamanti-system nfs-csi-diamanti-driver-tbxtx 2/2 Running 0 72m diamanti-system nfs-csi-diamanti-driver-tpqz5 2/2 Running 0 72m diamanti-system prometheus-v1-0 1/1 Running 0 73m diamanti-system prometheus-v1-1 1/1 Running 0 73m diamanti-system prometheus-v1-2 1/1 Running 0 73m diamanti-system snapshot-controller-59f5bf9945-dwb9b 1/1 Running 0 72m kube-system aws-load-balancer-controller-846977dbf5-k2p9h 1/1 Running 0 72m kube-system aws-load-balancer-controller-846977dbf5-rvnpv 1/1 Running 0 72m kube-system coredns-898f6ff68-54vd2 1/1 Running 0 73m kube-system coredns-898f6ff68-64f8q 1/1 Running 0 73m kube-system coredns-898f6ff68-7rrdr 1/1 Running 0 73m kube-system metrics-server-v1-6b45b6d676-nh9sr 1/1 Running 0 73m
To delete a cluster:
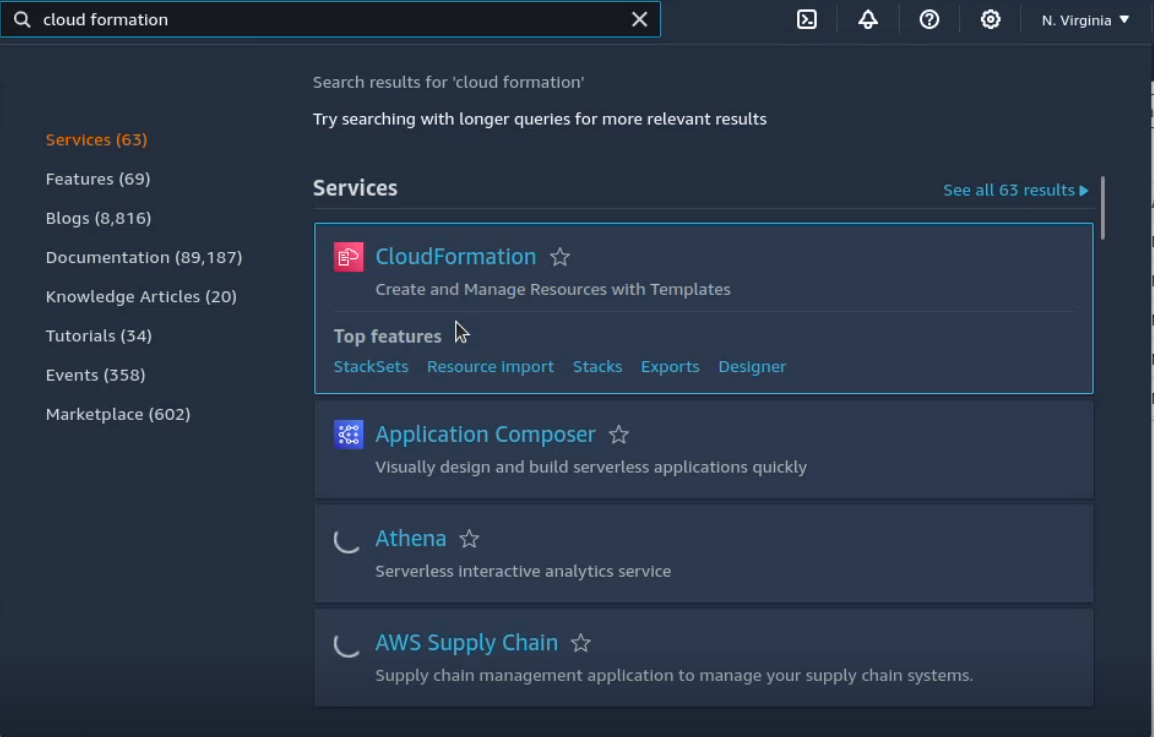
On AWS console, search and select Cloud Formation.
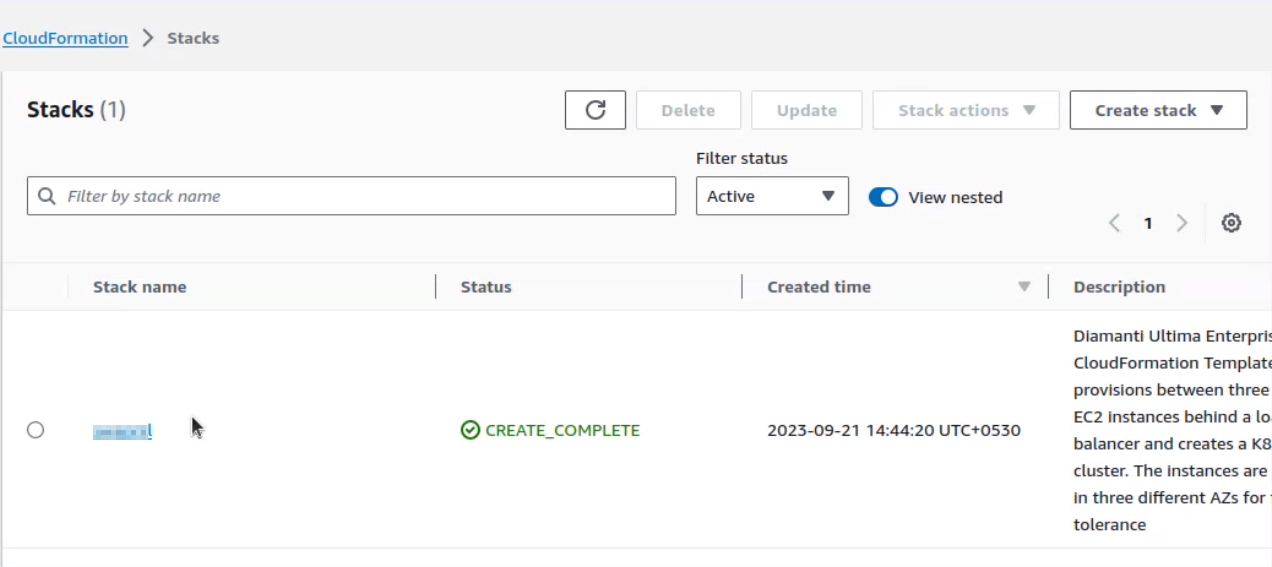
Select Stack, and select the cluster to delete.
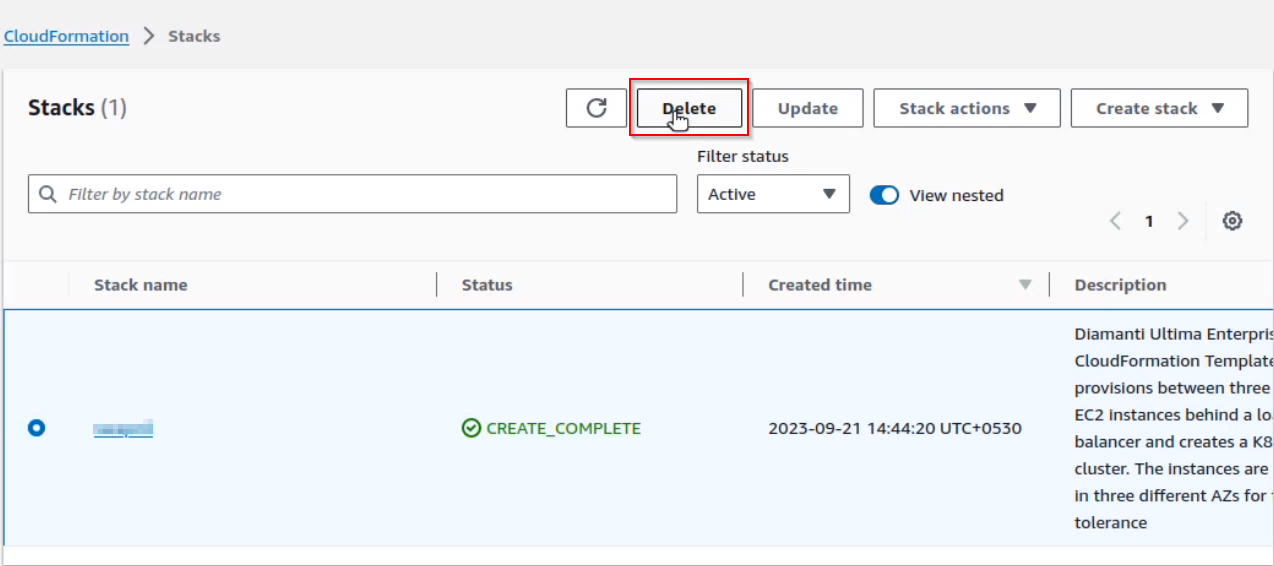
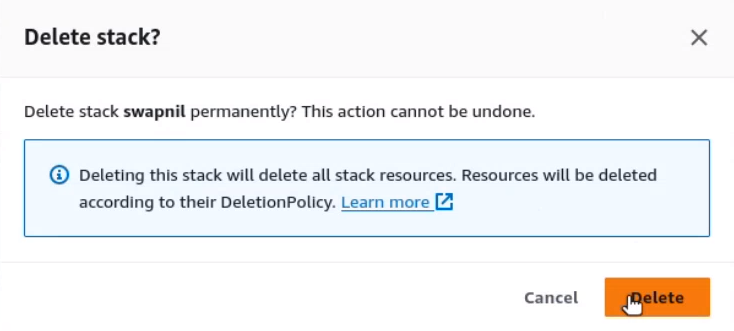
Select Delete, and then again select Delete in the confirmation box.
Add and remove Node
Adding a Node
Create new cft stack to add nodes to the cluster using aws-ue-add-node-cft.yaml
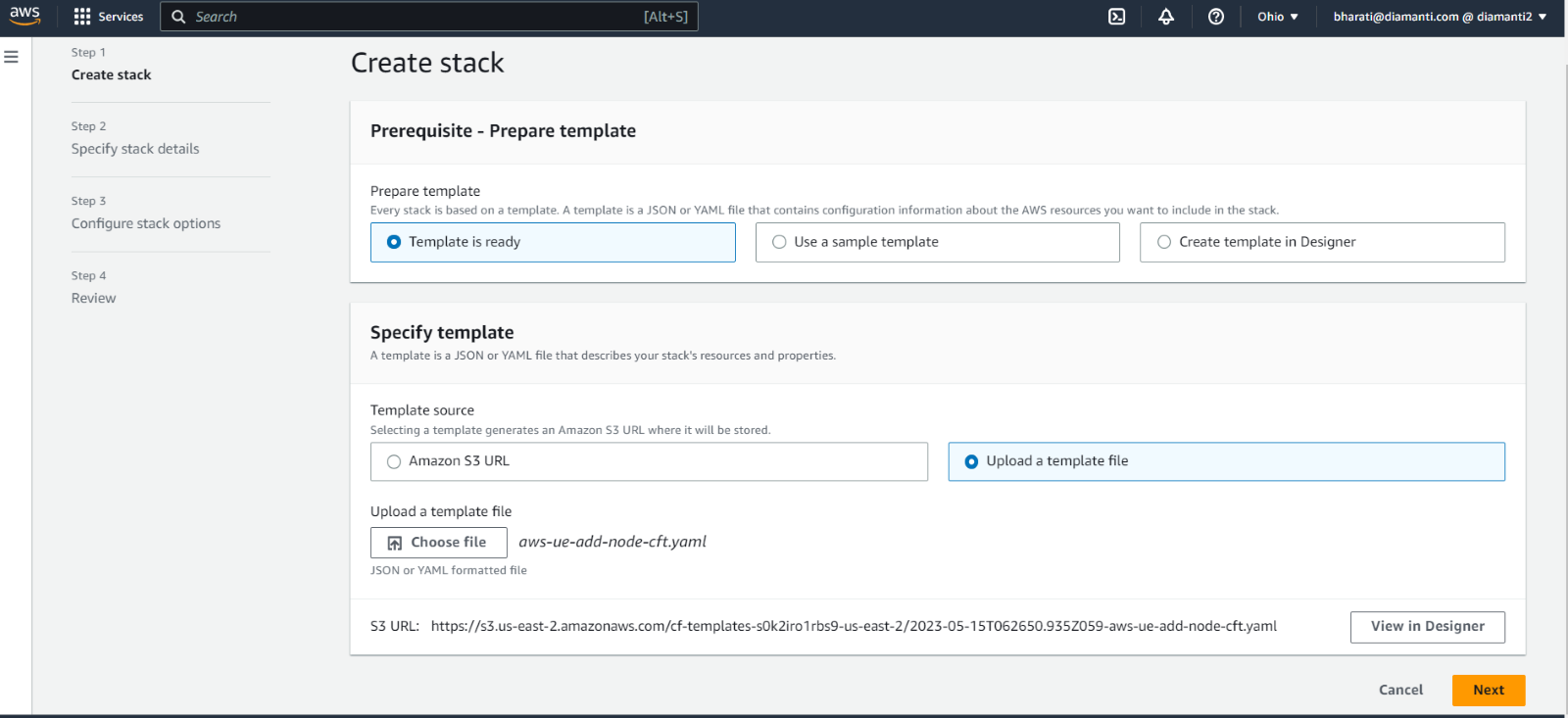
Enter the required details, and select Submit.
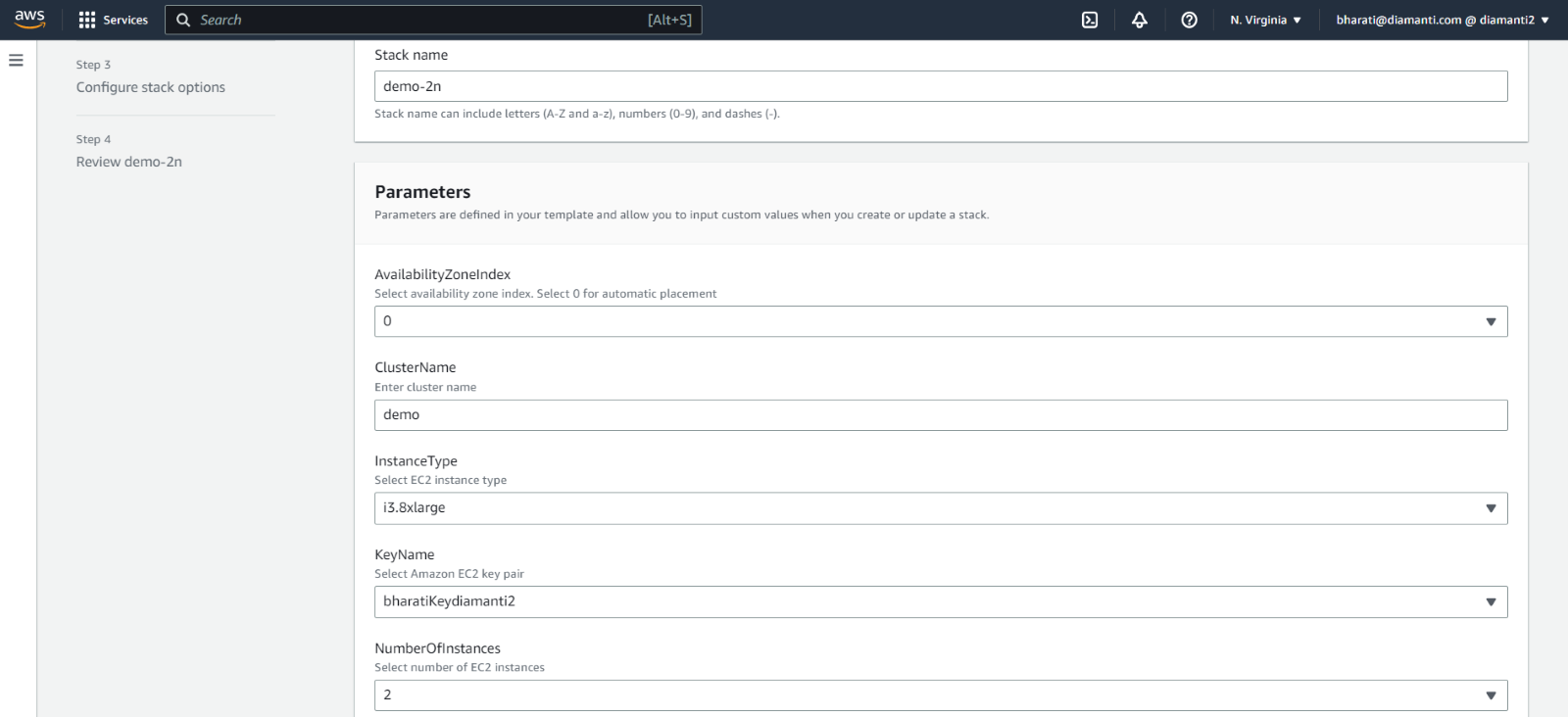
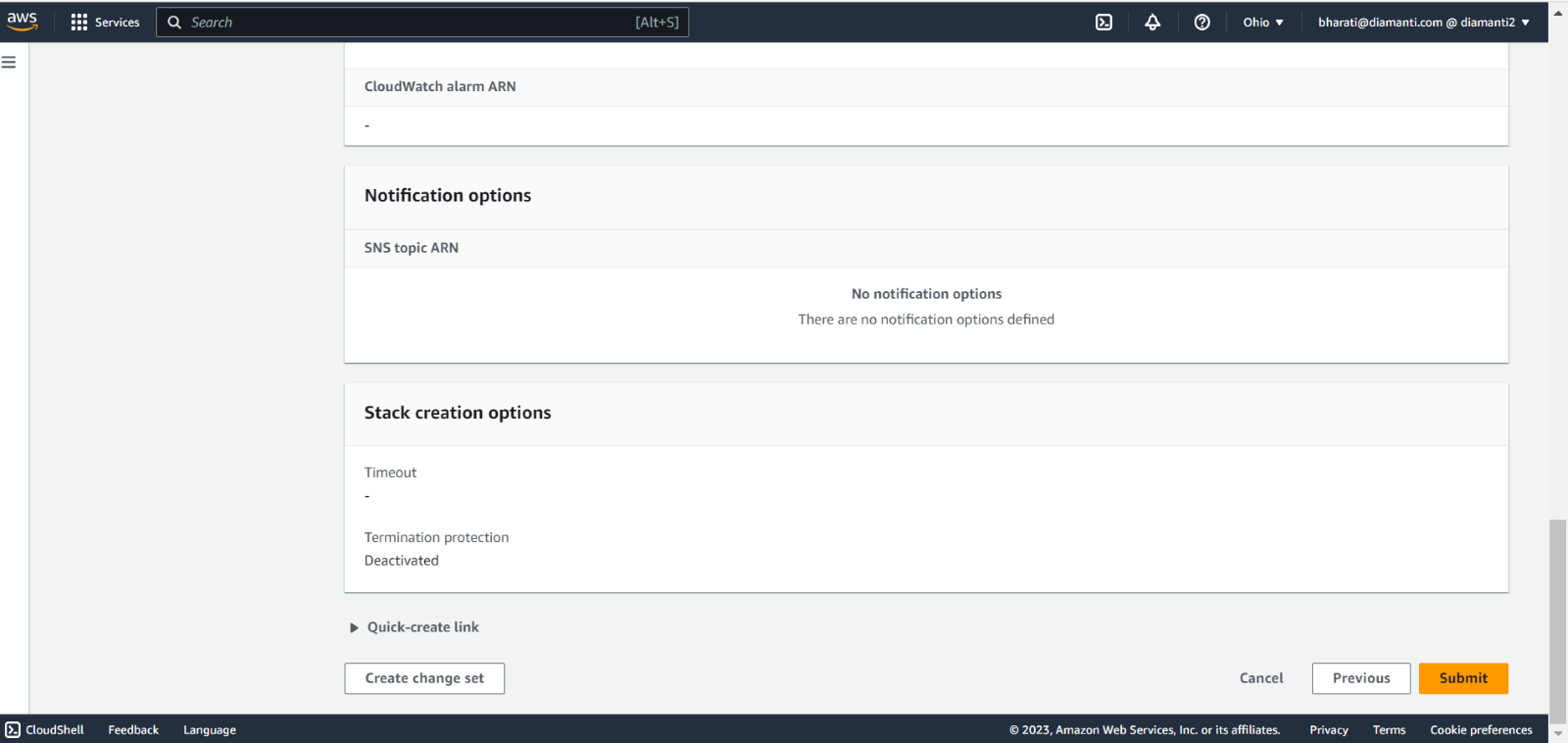
You can use the diamanti-add-node.sh script to add all stack instances to the cluster as worker nodes or master nodes or one node at a time.
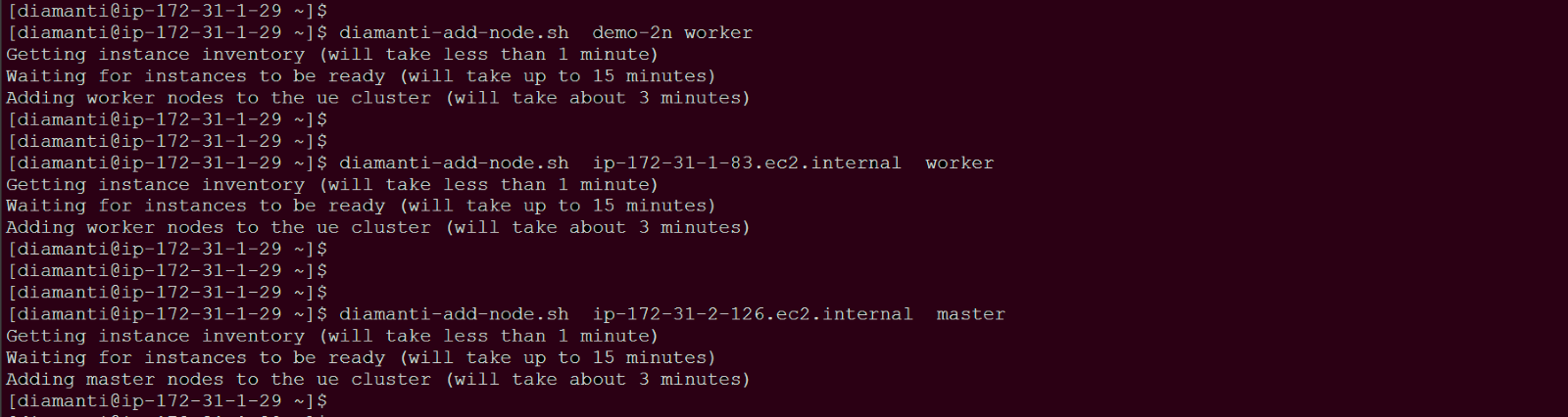
Add all instances of stack demo-2n (this stack has 2 instances) as worker nodes.
Add single instance ip-172-31-1-83.ec2.internal from the other stack as worker node.
Add single instance ip-172-31-2-126.ec2.internal from the other stack as master node.
Use
dctl cluster statusto check the cluster status.$ qaserv2:~> dctl cluster status Name : demo UUID : 81969e06-2d16-11ee-97a3-021c086df6e1 State : Created Version : 3.6.2 (62) Etcd State : Healthy Virtual IP : 3.208.113.169 Pod DNS Domain : cluster.local NAME NODE-STATUS K8S-STATUS ROLE MILLICORES MEMORY STORAGE SCTRLS LOCAL, REMOTE ip-172-31-1-253.ec2.internal Good Good master 100/64000 1.07GiB/256GiB 2.01GB/2.28TB 1/64, 2/64 ip-172-31-2-82.ec2.internal Good Good master* 7200/64000 25.26GiB/256GiB 2.01GB/2.28TB 0/64, 1/64 ip-172-31-3-195.ec2.internal Good Good master 7100/64000 25.07GiB/256GiB 2.01GB/2.28TB 0/64, 1/64
Removing a Node
To remove a node:
Drain the node before deleting it from the cluster.
Run the following command to delete a node.
diamanti-delete-node.sh.

Appendix:
Diamanti Ultima Enterprise 3.6.2 Supported Features
This appendix provides a feature matrix outlining supported and unsupported features available with Diamanti Ultima Enterprise.
Diamanti Ultima Enterprise Feature Matrix
Diamanti Ultima Enterprise supports the following features:
Feature |
Diamanti Ultima Enterprise |
|---|---|
ELB-Based cluster management |
Supported |
Overlay CNI |
Supported |
Container Storage Interface (CSI) |
Supported |
Volume Provisioning |
Supported |
Storage Mirroring |
Supported |
Storage Snapshots |
Supported |
Restore volume from Snapshot |
Supported |
Linked Clone Volumes |
Supported |
Backup Controller |
Supported |
User Management |
Supported |
RWO/RWX Support for Diamanti Volumes |
Supported |
Volume Resize |
Supported |
Licensing |
Supported |
Recovery from node Shutdown for AWS
The mirror plex present on the shutdown node needs to be removed from the volume, since shutdowns are not supported, and then the mirror plex has to be added again once the shutdown is complete.
You can perfom the following steps:
Turn on the node and log in. The node remains in the pending state after it is powered on.
Run the following command to check if the node is in pending status:
$ vagserv1:~/Inventoryfile> dcs Name : demo_cluster UUID : 90825a06-6366-11ee-8e4b-3868dd12a810 State : Created Version : 9.9.1 (50) Etcd State : Healthy Virtual IP : 172.16.19.136 Pod DNS Domain : cluster.local NAME NODE-STATUS K8S-STATUS ROLE MILLICORES MEMORY STORAGE SCTRLS LOCAL, REMOTE ip-172-31-1-184.ec2.internal Pending Good master 7100/40000 25.07GiB/192GiB 8.02TB/60.13TB 1/64, 2/64 ip-172-31-2-40.ec2.internal Good Good master 7100/40000 25.07GiB/192GiB 8.02TB/60.13TB 0/64, 1/64 ip-172-31-3-30.ec2.internal Good Good master* 7200/88000 25.26GiB/768GiB 21.51GB/3.83TB 0/64, 1/64$ vagserv1:~/Inventoryfile> dctl volume describe test-vol1 Name : test-vol1 Size : 21.51GB Encryption : false Node : [ip-172-31-3-30.ec2.internal, ip-172-31-1-184.ec2.internal, ip-172-31-2-40.ec2.internal] Label : diamanti.com/pod-name=default/v1-attached-manually Node Selector : <none> Phase : Available Status : Down Attached-To : dssserv14 Device Path : Age : 0d:0h:22m Perf-Tier : best-effort Mode : Filesystem Fs-Type : ext4 Scheduled Plexes / Actual Plexes : 3/3 Plexes: NAME NODES STATE CONDITION OUT-OF-SYNC-AGE RESYNC-PROGRESS DELETE-PROGRESS ---- ----- ----- --------- --------------- --------------- --------------- test-vol1.p0 ip-172-31-3-30.ec2.internal Up InUse test-vol1.p1 ip-172-31-1-184.ec2.internal Down Unknown test-vol1.p2 ip-172-31-2-40.ec2.internal Up InUseFormat the drives of that node. Upon running the driveformat script, the node will reboot.
Run the following command to drain the node:
vagserv1:~> kubectl drain ip-172-31-1-184.ec2.internal --ignore-daemonsets node/dssserv14 already cordoned Warning: ignoring DaemonSet-managed Pods: diamanti-system/collectd-v0.8-x87qb, diamanti-system/csi-diamanti-driver-sgppg, diamanti-system/dcx-ovs-daemon-pgphr, diamanti-system/diamanti-dssapp-medium-5gxr7, diamanti-system/nfs-csi-diamanti-driver-m66xt evicting pod kube-system/coredns-565758fd8d-c4cgv evicting pod diamanti-system/alertmanager-0 evicting pod diamanti-system/prometheus-v1-2 pod/alertmanager-0 evicted pod/prometheus-v1-2 evicted pod/coredns-565758fd8d-c4cgv evicted node/ip-172-31-1-184.ec2.internal drainedRun the following command to format the drives of that node:
$ sudo format-dss-node-drives.sh -n ip-172-31-1-184.ec2.internal ######################### WARNING ############################ # # # Please make sure the node is cordon & drained. # # # # This will erase all the data and objects from this node. # # # # After drive format complete it will reboot the node. # # # ################################################################ Do you want to proceed? [Y/n] Y Yes INFO: Start drive format on node ip-172-31-1-184.ec2.internal INFO: Cluster login exist INFO: Ready to format drives from node ip-172-31-1-184.ec2.internal with count: 100 0000:d9:00.0 (8086 0b60): uio_pci_generic -> nvme 0000:d8:00.0 (8086 0b60): uio_pci_generic -> nvme 0000:5f:00.0 (8086 0b60): uio_pci_generic -> nvme 0000:5e:00.0 (8086 0b60): uio_pci_generic -> nvme Hugepages node hugesize free / total node0 1048576kB 0 / 0 node0 2048kB 194 / 2048 node1 1048576kB 0 / 0 node1 2048kB 1166 / 2048 NVMe devices BDF Vendor Device NUMA driver Device name 0000:5e:00.0 8086 0b60 0 nvme nvme3 0000:5f:00.0 8086 0b60 0 nvme nvme2 0000:d8:00.0 8086 0b60 1 nvme nvme1 0000:d9:00.0 8086 0b60 1 nvme nvme0 INFO: Formating drives ... INFO: Device format started on nvme0n1 INFO: Device format started on nvme1n1 INFO: Device format started on nvme2n1 INFO: Device format started on nvme3n1 #####100+0 records in 100+0 records out 53687091200 bytes (54 GB, 50 GiB) copied, 24.6162 s, 2.2 GB/s 100+0 records in 100+0 records out 53687091200 bytes (54 GB, 50 GiB) copied, 24.6719 s, 2.2 GB/s 100+0 records in 100+0 records out 53687091200 bytes (54 GB, 50 GiB) copied, 24.8202 s, 2.2 GB/s 100+0 records in 100+0 records out 53687091200 bytes (54 GB, 50 GiB) copied, 25.1053 s, 2.1 GB/s INFO: Drive format completed INFO: Total time took: 26 seconds WARN: Restarting the node in 10 seconds Restarting in 0 sec n 1 sec n 2 sec n 3 sec n 4 sec n 5 sec n 6 sec n 7 sec n 8 sec n 9 sec 10 sec Connection to ip-172-31-1-184.ec2.internal closed by remote host. Connection to ip-172-31-1-184.ec2.internal closed. ------------------ Run the following command to uncordon the node: .. code:: vagserv1:~> kubectl uncordon ip-172-31-1-184.ec2.internal node/ip-172-31-1-184.ec2.internal uncordonedRun the following command to find out the plex name of the shutdown node.
vagserv1:~> dctl volume describe test-vol1 Name : test-vol1 Size : 21.51GB Encryption : false Node : [ip-172-31-3-30.ec2.internal ip-172-31-1-184.ec2.internal ip-172-31-2-40.ec2.internal] Label : <none> Node Selector : <none> Phase : Available Status : Available Attached-To : Device Path : Age : 0d:1h:34m Perf-Tier : best-effort Mode : Filesystem Fs-Type : ext4 Scheduled Plexes / Actual Plexes : 3/3 Plexes: NAME NODES STATE CONDITION OUT-OF-SYNC-AGE RESYNC-PROGRESS DELETE-PROGRESS ---- ----- ----- --------- --------------- --------------- --------------- test-vol1.p0 ip-172-31-3-30.ec2.internal Up InSync test-vol1.p1 ip-172-31-1-184.ec2.internal Down Detached 0d:1h:1m test-vol1.p2 ip-172-31-2-40.ec2.internal Up InSyncRun the following commnd to delete the plex of the volume from the other node.
$ dctl volume plex-delete test-vol1 p1 vagserv1:~> dctl volume describe test-vol1 Name : test-vol1 Size : 21.51GB Encryption : false Node : [ip-172-31-3-30.ec2.internal ip-172-31-1-184.ec2.internal ip-172-31-2-40.ec2.internal] Label : <none> Node Selector : <none> Phase : Available Status : Available Attached-To : Device Path : Age : 0d:1h:34m Perf-Tier : best-effort Mode : Filesystem Fs-Type : ext4 Scheduled Plexes / Actual Plexes : 3/3 Plexes: NAME NODES STATE CONDITION OUT-OF-SYNC-AGE RESYNC-PROGRESS DELETE-PROGRESS ---- ----- ----- --------- --------------- --------------- --------------- test-vol1.p0 ip-172-31-3-30.ec2.internal Up InSync test-vol1.p2 ip-172-31-2-40.ec2.internal Up InSyncRun the following command to add the plex back to the volume.
$ dctl volume update test-vol1 -m 3 vagserv1:~> dctl volume describe test-vol1 Name : test-vol1 Size : 21.51GB Encryption : false Node : [ip-172-31-3-30.ec2.internal ip-172-31-1-184.ec2.internal ip-172-31-2-40.ec2.internal] Label : <none> Node Selector : <none> Phase : Available Status : Available Attached-To : Device Path : Age : 0d:1h:34m Perf-Tier : best-effort Mode : Filesystem Fs-Type : ext4 Scheduled Plexes / Actual Plexes : 3/3 Plexes: NAME NODES STATE CONDITION OUT-OF-SYNC-AGE RESYNC-PROGRESS DELETE-PROGRESS ---- ----- ----- --------- --------------- --------------- --------------- test-vol1.p0 ip-172-31-3-30.ec2.internal Up InSync test-vol1.p1 ip-172-31-1-184.ec2.internal Up InSync test-vol1.p2 ip-172-31-2-40.ec2.internal Up InSync